


“이전에 듣던 지점부터 다시 재생하고 싶어요.”
유저 테스트 기간 동안 가장 많이 받은 피드백이었습니다.
사용자들은 중간에 멈춘 콘텐츠를 다시 찾는 과정에서 반복적인 불편함을 겪고 있었습니다.
이 요구를 그대로 구현하면, 사용자의 상태를 아주 짧은 주기로 지속적으로 저장해야 하는 문제와 마주하게 됩니다.
그러나 모든 요청을 즉시 데이터베이스에 기록하는 방식은, 요청 수가 늘어날수록 쓰기 부하와 지연을 빠르게 증폭시키며, 시스템 확장 시 가장 먼저 한계를 드러냅니다.
따라서 빈번한 쓰기 요청은 즉시 저장해야 할 대상이 아니라, 조절하고 다뤄야 할 대상이 됩니다.
중간에 완충 지점을 두고 불필요한 중복을 제거한 뒤, 의미 있는 시점에 묶어서 저장하는 구조가 필요합니다.
더 나아가 서버가 여러 대로 확장되더라도, 모든 인스턴스가 동일한 상태를 기준으로 동작하고 순서 역전이나 데이터 손실이 발생하지 않는 구조여야 합니다.
이 글은 이러한 문제의식에서 출발해, 단순한 저장 방식에서부터
버퍼링 → 중복 제거 → 공유 상태 관리 → 동시성 제어 → 장애 대응으로 이어지는 점진적인 개선 과정을 통해,
빈번한 쓰기 요청을 어떻게 효율적이고 안정적으로 처리할 수 있었는지를 다룹니다.
Chapter 1. 시작은 단순했다
가장 직관적인 방법
첫 구현은 매우 단순했습니다.
클라이언트가 3초마다 현재 상태를 보내면, 이를 즉시 데이터베이스에 저장하는 방식이었습니다.
@PostMapping("/playinghistory")
public void saveHistory(@RequestBody HistoryRequest request) {
PlayingHistory history = new PlayingHistory(
request.getUserUuid(),
hearit,
request.getLastPlayTime()
);
playingHistoryRepository.save(history);
}금방 드러난 문제
사용자가 늘어나자 문제가 드러나기 시작했습니다.
100명의 사용자 = 초당 약 33회의 DB 쓰기
100명이 동시에 콘텐츠를 소비하면 초당 약 33번의 UPDATE 쿼리가 발생합니다. 사용자가 1,000명으로 늘어나면 이 수치는 초당 333회까지 증가합니다. 문제는 단순히 쿼리 수가 늘어나는 것이 아니었습니다.
평균 100ms가 소요되는 DB 쓰기 작업을 요청 처리 흐름에서 직접 기다려야 했고,
이는 곧 응답 지연으로 이어졌습니다. 쓰기 부하 증가는 곧바로 사용자 경험 저하로 연결되는 구조였습니다.
“DB에 바로 저장하는 방식은 오래 갈 수 없다.
중간에 완충 지점이 필요하다.”
Chapter 2. 첫 번째 최적화: 큐 기반 버퍼링
버퍼를 두자

해결책은 비교적 명확했습니다. 요청이 들어오면 일단 메모리에 쌓아두고, 주기적으로 한 번에 처리하는 방식입니다.
@Component
public class HistoryQueueBuffer {
private final BlockingQueue<PlayingHistory> queue = new LinkedBlockingQueue<>();
public void add(PlayingHistory history) {
queue.offer(history); // 즉시 응답
}
@Scheduled(fixedDelay = 1000)
public void flush() {
List<PlayingHistory> batch = new ArrayList<>();
queue.drainTo(batch);
if (!batch.isEmpty()) {
playingHistoryRepository.saveAll(batch);
}
}
}이 방식으로 DB에 전달되는 요청 수를 크게 줄일 수 있었고, 응답 속도 역시 즉각적으로 개선되었습니다.
발생한 문제점
하지만 메모리 사용량을 관찰하던 중 이상한 점을 발견했습니다.
사용자가 같은 콘텐츠를 계속 소비하는 동안, 큐에는 데이터가 끝없이 쌓이고 있었습니다.
불필요한 중복 데이터가 큐를 채우고 있었고, 요청이 몰릴 경우 큐가 무한정 커지며 결국 OOM으로 이어질 수 있는 구조였습니다.
“순서대로 처리할 필요가 없다.
중요한 건 최신 값이다.”
Chapter 3. 두 번째 최적화: Map으로 중복 제거
자료구조를 바꾸자
큐는 순서 보장에는 적합했지만, 이 문제에서 중요한 것은 순서가 아니라 최신 상태 유지였습니다.
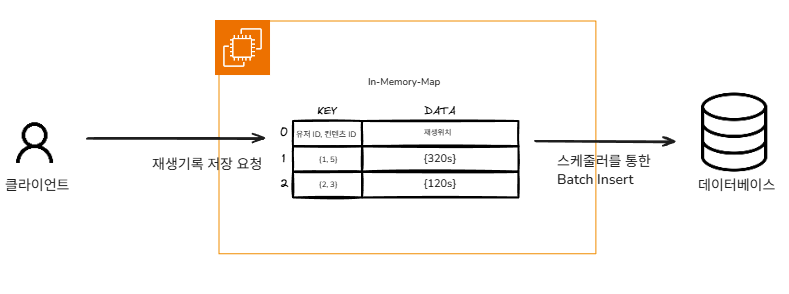
버퍼를 Map 기반 구조로 변경해, 동일한 대상에 대해서는 항상 최신 값만 유지하도록 했습니다.
결과
- 메모리 사용량 안정화
- 중복 데이터 제거
또 다른 문제: 확장 시 깨지는 최신성
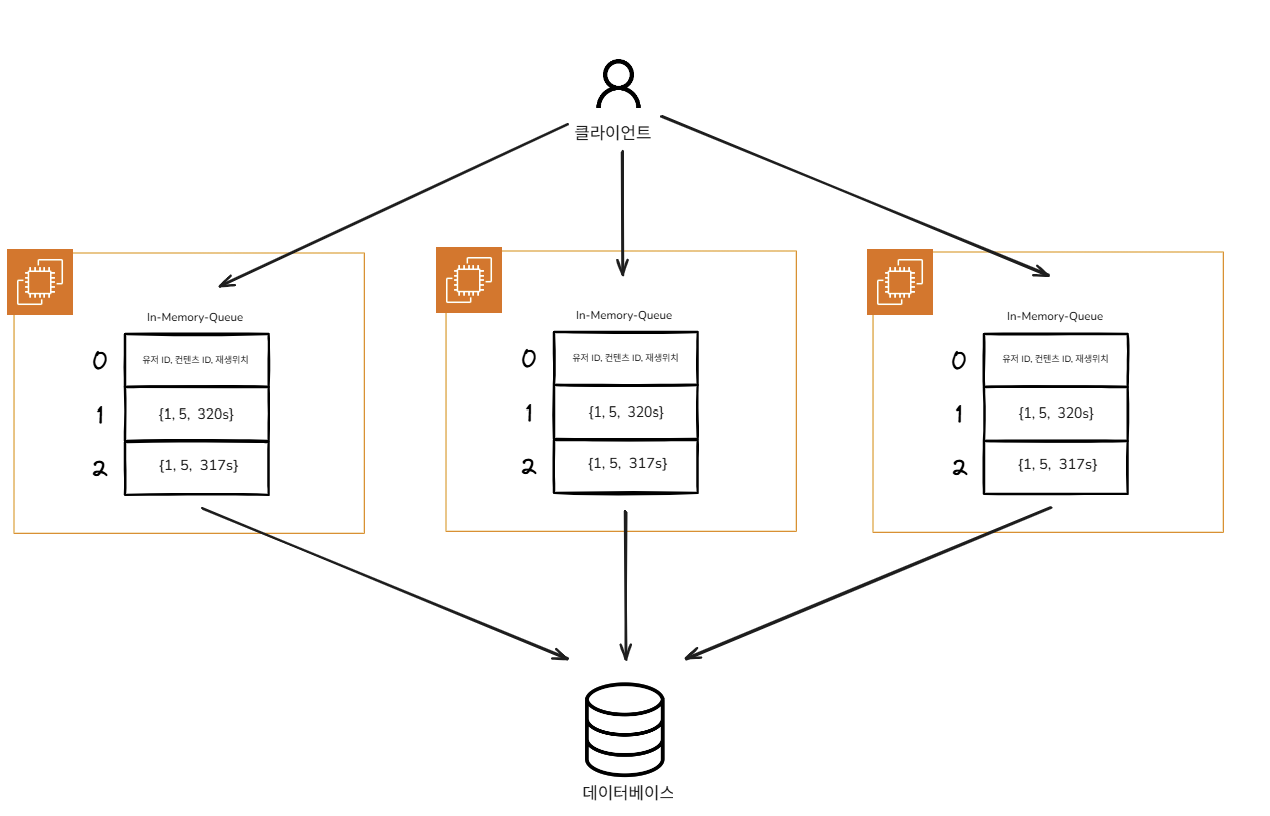
이제 서버를 여러 대로 늘릴 준비가 되었다고 생각했습니다. 그러나 곧 새로운 문제가 드러났습니다.
타임머신 버그 시나리오
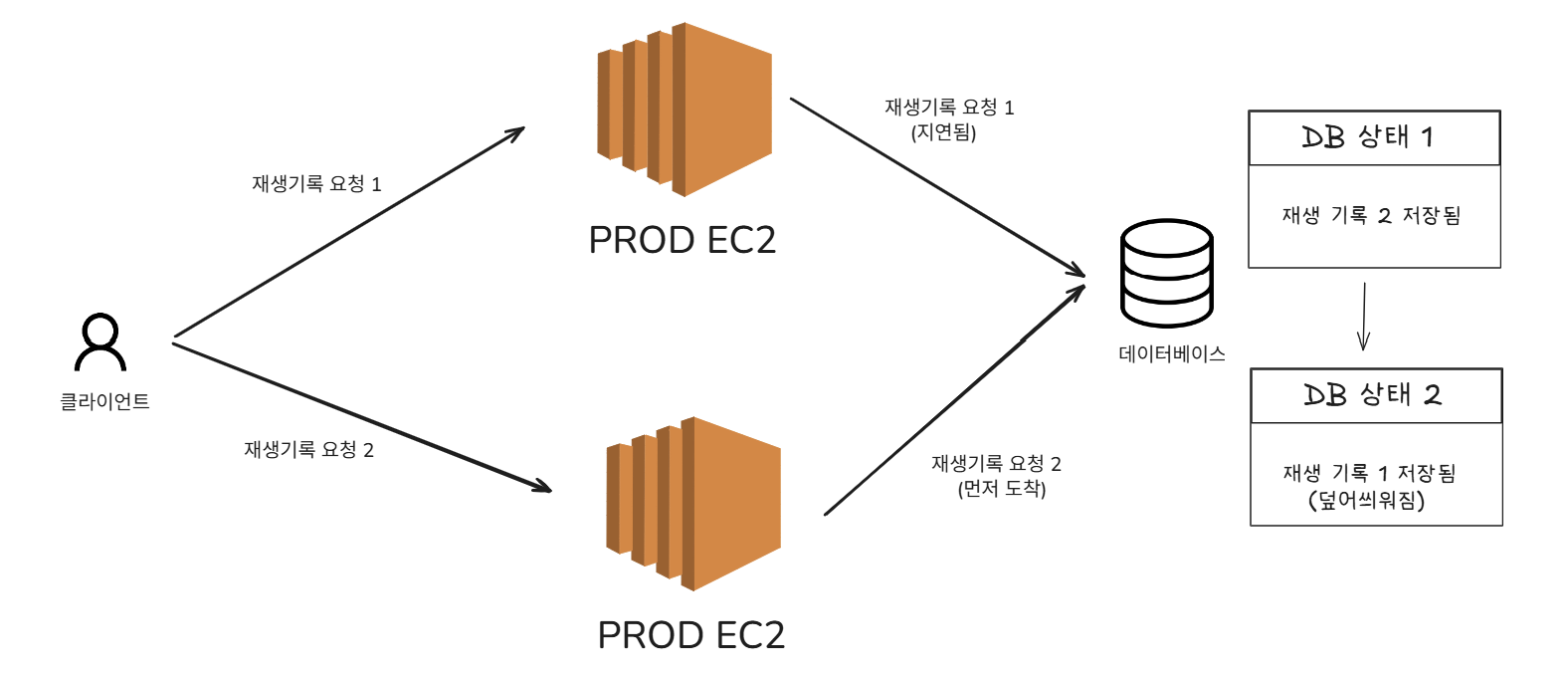
| 시간 | 서버 | 동작 | 결과 |
|---|---|---|---|
| 10:00:01 | Server A | 10초 저장 | ✅ |
| 10:00:05 | Server B | 20초 저장 | ✅ |
| 10:00:06 | Server B | DB에 20초 저장 | ✅ |
| 10:00:07 | Server A | DB에 10초 저장 | ❌ |
최신 상태였던 20초가 과거 상태인 10초로 덮어씌워졌습니다.
이 문제의 본질은 단순한 동시성 문제가 아니었습니다.
각 서버가 자신만의 메모리 버퍼를 기준으로 “최신”을 판단하고 있었기 때문입니다.
Chapter 4. 왜 DB 락으로는 부족한가
첫 번째 떠오른 해결책: DB 비관적 락
DB에 저장할 때 락을 걸어 순서를 보장하는 방법을 먼저 떠올렸습니다.
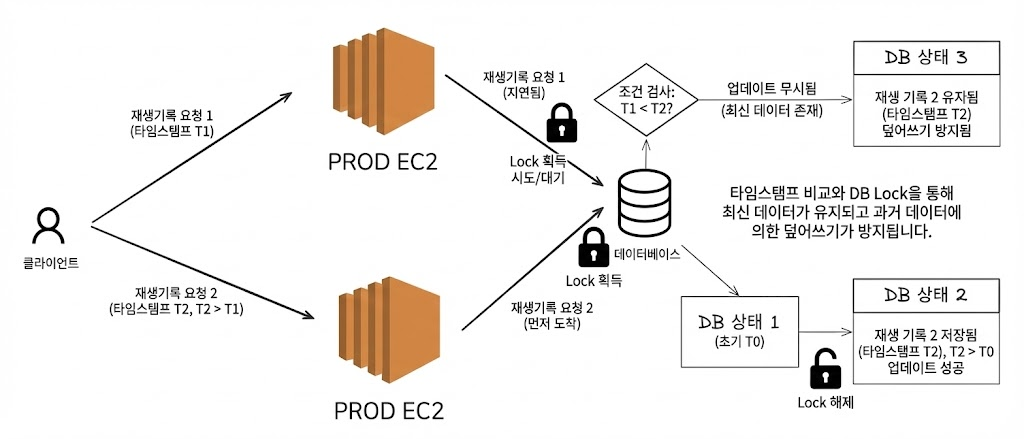
장점
- 구현 단순
- 추가 인프라 불필요
- 정합성 보장
근본적인 한계
하지만 DB 락은 DB에 쓰는 순간의 충돌만 막을 뿐, 각 서버가 독립적인 버퍼를 가진 구조 자체는 바꾸지 못했습니다.
결과:
- 중복 제거 실패
- 불필요한 DB 쓰기
- 락 경쟁으로 인한 성능 저하
- 커넥션 풀 압박
“DB 락은 버그를 막을 수는 있지만, 구조를 해결하지는 못한다.”
Chapter 5. Redis: 공유 버퍼라는 해답
모든 서버가 같은 상태를 보게 하자
문제의 핵심은 명확했습니다. 각 서버가 독립적으로 판단하지 않도록, 하나의 공유 상태를 두자.

Redis는 이 요구를 가장 단순하게 충족할 수 있는 선택지였습니다.
여러 서버가 동일한 데이터를 기준으로 중복을 제거하고, 최신 값만 유지할 수 있었습니다. Redis를 선택한 이유는 “빠르기 때문”이 아니라, 공유 버퍼라는 역할을 가장 단순하게 수행할 수 있었기 때문입니다.
Chapter 6. Redis 내부 동시성: Lua vs 분산 락
Redis를 도입하며 서버 간 타임머신 버그는 사라졌지만 Redis 내부에서도 새로운 동시성 문제가 나타났습니다.
조회 → 비교 → 저장 사이에 다른 요청이 끼어들며 최신 값이 다시 덮어씌워질 수 있는 상황이었습니다.
선택지 비교
- Lua Script: 빠르고 원자적이지만 유지보수 난이도 높음
- 분산 락: 약간 느리지만 코드 관리와 협업에 유리
최종 선택
public void add(PlayingHistory history, long clientEventTime) {
String lockKey = "lock:playing_history:" + field;
RLock lock = redissonClient.getLock(lockKey);
try {
if (lock.tryLock(1000, 3000, TimeUnit.MILLISECONDS)) {
try {
// 1. Redis에서 기존 값 조회
String existing = redisTemplate.opsForHash()
.get(REDIS_HASH_KEY, field);
// 2. 비교 후 더 최신 값만 저장
if (existing == null || isNewer(existing, clientEventTime)) {
PlayValue newValue = new PlayValue(history, clientEventTime);
String newJson = objectMapper.writeValueAsString(newValue);
redisTemplate.opsForHash()
.put(REDIS_HASH_KEY, field, newJson);
}
} finally {
lock.unlock();
}
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new BufferException("재생 기록 저장 중 오류 발생");
}
}이 작업은 사용자에게 실시간으로 노출되지 않는 비동기 작업이었고, 장기적인 유지보수와 협업을 고려해 분산 락을 선택했습니다.
Chapter 7. Rename 스냅샷 전략
@Override
public void flush() {
if (!hasDataToFlush()) return;
try {
// 1. 이전 flush 실패 시 복구
checkAndRestorePreviousFlush();
// 2. 스냅샷 생성 (RENAME - 원자적 연산)
redisTemplate.rename(
"playing_history",
"playing_history:flushing"
);
// 3. 스냅샷 데이터 조회
Map<String, String> snapshot = redisTemplate
.opsForHash()
.entries("playing_history:flushing");
// 4. DB 저장
List<PlayingHistory> histories = parseToHistories(snapshot);
commandRepository.bulkInsert(histories);
// 5. 스냅샷 삭제
redisTemplate.delete("playing_history:flushing");
} catch (Exception e) {
log.error("Flush 실패, 스냅샷 복원 시도", e);
restoreSnapshot();
}
}Flush 중에도 새로운 요청은 계속 들어옵니다. 단순 삭제 방식은 데이터 유실로 이어질 수 있었습니다.
Redis의 RENAME 명령을 활용해 처리 대상과 신규 데이터를 원자적으로 분리했습니다.
Chapter 8. 장애 상황에서도 멈추지 않기
Redis 장애가 곧바로 서비스 중단으로 이어져서는 안 됩니다. 그래서 3단계 Fallback 구조를 설계했습니다.
- Redis
- 로컬 메모리
- 로깅
@Primary
@Component
public class PlayingHistoryBufferFacade implements PlayingHistoryBuffer {
private final PlayingHistoryRedisBuffer primaryStorage;
private final PlayingHistoryMapBuffer fallbackStorage;
@Override
public void add(PlayingHistory history, long clientEventTime) {
try {
// 1차: Redis Buffer (모든 서버 공유)
primaryStorage.add(history, clientEventTime);
} catch (Exception e) {
log.warn("Redis 장애, Fallback으로 전환", e);
try {
// 2차: Local Memory Map (서버별 독립)
fallbackStorage.add(history, clientEventTime);
} catch (Exception fallbackException) {
// 3차: 로깅만 (서비스 계속)
log.error("Fallback도 실패, 데이터 유실", fallbackException);
// 사용자에게는 정상 응답 (200 OK)
}
}
}
@Override
public void flush() {
flushStorage("Primary", primaryStorage);
flushStorage("Fallback", fallbackStorage);
}
}기능은 축소되더라도, 서비스는 계속 동작하도록 설계했습니다.
Chapter 9. 스케줄러 중복 실행 방지
여러 서버에서 동시에 flush가 실행되지 않도록 ShedLock을 통해 단 하나의 서버만 작업을 수행하도록 보장했습니다.
@Component
@RequiredArgsConstructor
public class PlayingHistoryFlushScheduler {
private final PlayingHistoryBuffer buffer;
@Scheduled
@SchedulerLock(
name = "PlayingHistoryFlushScheduler",
lockAtMostFor = "10s",
lockAtLeastFor = "1s"
)
public void scheduleFlush() {
buffer.flush();
}
@PreDestroy
public void shutdown() {
buffer.flush(); // 종료 시 마지막 flush
}
}
참고 자료
'개발' 카테고리의 다른 글
| AI 도구를 활용해 백오피스 자동화하기 (3) | 2026.01.19 |
|---|---|
| JPA Auditing 환경에서 시간 로직을 테스트 가능하게 만들기 (0) | 2025.12.16 |
| EC2 서버 설정 파일을 Git으로 관리하며 자동화하기 (0) | 2025.12.01 |
| 신뢰할 수 있는 API 문서를 만들기: REST Docs + Swagger UI 하이브리드 전략 (0) | 2025.11.21 |
| 개발에서의 추상화, 그리고 삶의 추상화 (2) | 2025.04.09 |
